You might not need a CRDT
• Paul Butler
Conflict-free replicated data types (CRDTs) are a family of replicated data structures.
CRDTs differ from simple leader/follower replication in that they do not designate an authoritative source-of-truth that all writes must pass through. Instead, all replicas are treated as equal peers. Each replica may be modified locally, and changes to any replica are propagated to the others.
In developer discourse, the term CRDT sometimes gets thrown around as a synecdoche for a broader set of techniques to enable Figma-like collaborative features. But when we started talking to dozens of companies building ambitious browser-based apps, we found it rare for apps to use true CRDTs to power multiplayer collaboration.
In this post, I’ll first give some high-level context on CRDTs, and then talk about why we often find other approaches used in practice.
Synchronizing State
The core problem that multiplayer apps need to solve is maintaining shared state. If you and I are both editing the same document, I should see your changes in real-time and vice versa.
At the code level, this means that there is some data structure (say, a tree or list) representing the document which exists in multiple locations: one for each user with the document open. Changes made on one copy need to be reflected by the others, as quickly as possible.
One way to accomplish this is to serialize each change and broadcast it over the network. If you and I are collaborating on a todo list, and I mark the fifth item as done, my replica emits some serialized event meaning “Mark item #5 as done”. If you then add an item ‘get groceries’ in the third position, your replica emits an event meaning “Insert ‘get groceries’ before item #3”.
This works fine as long as enough time passes for each of us to receive the others’ changes before making our own change. If not, things break down.
Suppose we start a collaboration session at time 0 with a list of two items, Get groceries and Do laundry. At time 1, I mark Do laundry as done, and you simultaneously add a new item called Clean kitchen to the middle of the list. When my replica sees your edit at time 2, your change is appropriately applied on top of mine and I see the correct state. But when my change (“mark item 2 as done”) reaches your replica, “item 2” refers to the item you just added, not the one I actually checked. Our lists have diverged.
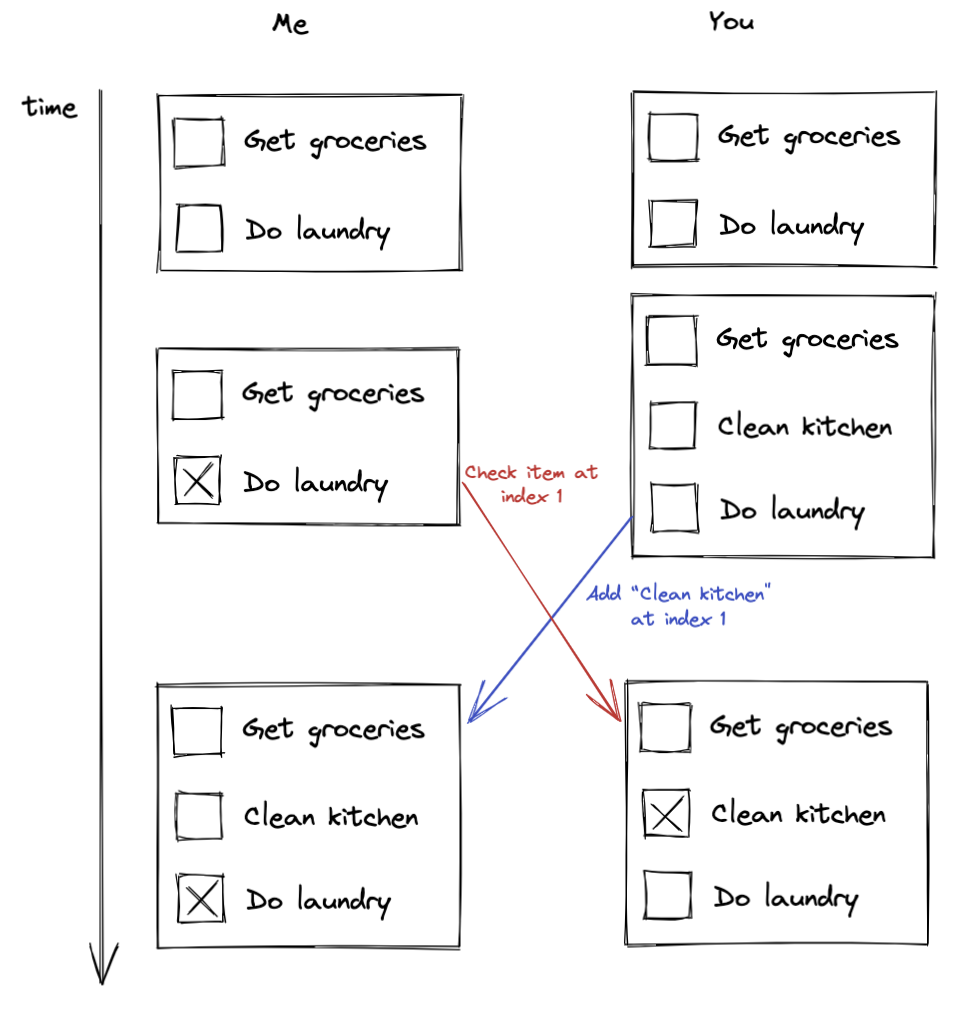
The problem comes down to the interplay of two facts:
- Operations on our data structure are not commutative: the result of applying them depends on the order in which they are applied.
- Our operations are unordered. Each replica might receive and apply the changes in a different order.
If we can design a system in which either one of these statements is no longer true, we can ensure that our data structure is eventually-consistent. Each of the two items represents a different path we can take.
Path #1 represents CRDTs. Broadly, you can think of CRDTs (specifically, operation-based CRDTs) as a family of useful data structures (lists, sets, maps, counters) carefully designed such that all operations are commutative. I'm brushing over some details, but it’s a useful mental model for understanding the shape of the problem that CRDTs solve.
Path #2 in its pure form represents state machine replication. We ensure that each replica receives changes in the same “global” order, and apply change on each replica in that same global order. This ensures that each replica stays in sync, even if change operations are not commutative.
In practice, most of the systems we’ve looked at could be described as hybrid approaches that borrow ideas from both paths. They represent operations as commutative where possible so that they can apply them immediately on the local replica without worrying about where they appear in the global order, but they ultimately depend on a global order for convergence.
Aside: Convergence vs. Correctness
Both paths will allow us to ensure that each replica converges on the same state, but that alone does not guarantee that this state is the “correct” state from the point of view of user intent.
For example, in the to-do example, it’s possible that the server sees your “add Clean kitchen” change before my “check item #1” change, and incorrectly marks the new item as checked.
A typical solution in this case (applicable to both paths) is to generate a random UUID for each item when it is created, so that my change is instead represented as “check item 8e50…3f34”, and is applied correctly regardless of where the item I intend to check is in the list by the time my change is applied on a replica.
State machine replication is not a silver bullet; we still need to be thoughtful about how change operations apply when the underlying data has changed. Our Aper Rust library is an experiment in seeing how much of this can be generalized into a data structures library.
Global order
So far, our assumption has been that we have a reliable but unordered broadcast channel (in practice, it may be a gossip protocol on top of a mesh network). This is a fitting assumption for a true peer-to-peer app, where it is difficult to get every peer to come to a consensus about the “true” ordering of events. CRDTs are complex, in both the runtime overhead and cognitive load senses, but in a peer-to-peer environment, this is a necessary cost.
In contrast, browsers are inherently not peer-to-peer. To run an application from the web, you connect to a server. Since the server is centralized anyway, we can have it enforce a global ordering over the events. That is, every replica receives events in the same orer. With this, we can sidestep the need to pay the CRDT complexity tax.
Evan Wallace of Figma writes:
Figma isn't using true CRDTs […]. CRDTs are designed for decentralized systems where there is no single central authority to decide what the final state should be. There is some unavoidable performance and memory overhead with doing this. Since Figma is centralized (our server is the central authority), we can simplify our system by removing this extra overhead and benefit from a faster and leaner implementation.
With a global order, we don’t need to bend over backwards to ensure that data mutations are commutative, we can use the global order to apply them in the same order on every replica.
(A modern web application is likely deployed to multiple servers, not one, which complicates using “the server” as a source of truth. Figma solves this by routing messages to a dedicated process for each live document. Plane and Jamsocket generalize that approach.)
Composition
Generic data structures, like lists and maps, are often used as a foundation for building more complex data structures, like graphs and relational data tables.
It’s tempting to wonder if we could just swap out their underlying data structures for the equivalent CRDTs, and automatically gain a CRDT for our composite data type.
Unfortunately, these composite data types usually rely on the fact that all changes to the underlying data structure go through a particular code path. This is necessary to enforce invariants that they rely on.
For example, suppose our document state represents a directed acyclic graph as a list, where elements can reference other items by index. Even if each replica ensures that changes made to it don’t introduce a cycle, two innocent changes made concurrently on two replicas could combine to break the invariant.
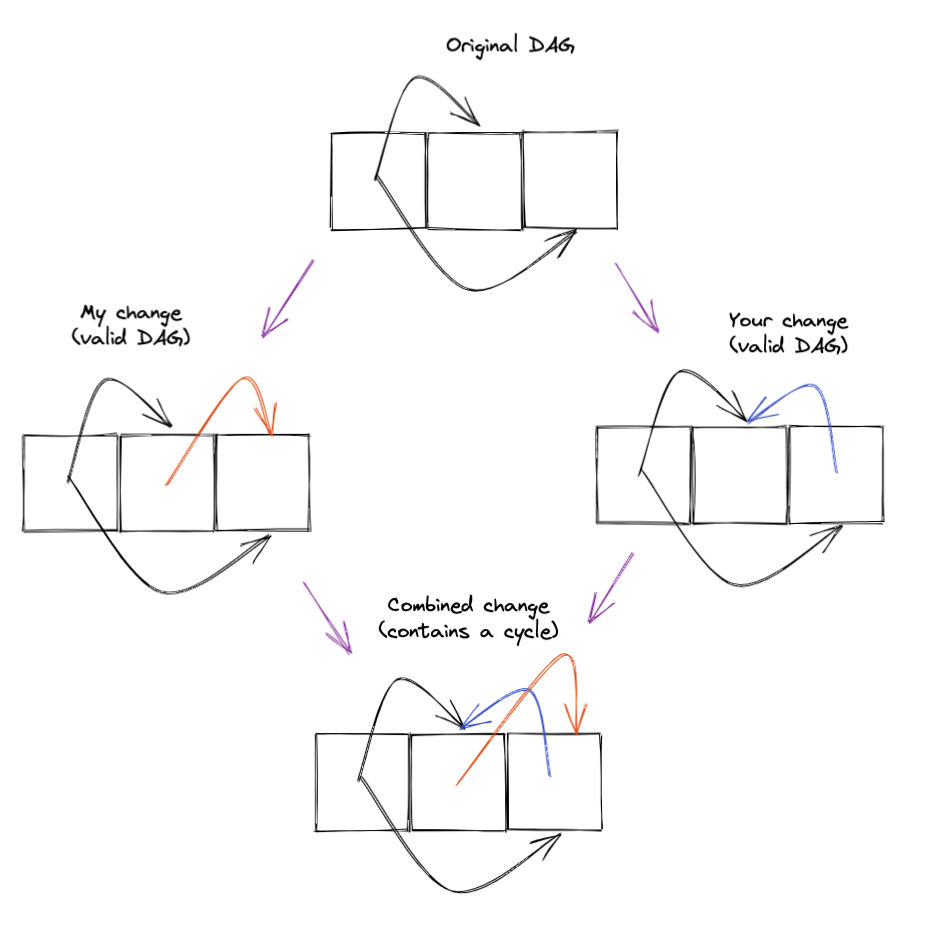
If we naively try to replicate this tree by replicating the underlying list CRDT, we lose control of this invariant. Two concurrent modifications may result in a cycle when they are combined, even if neither introduces a cycle in isolation.
When we instead have a global order of changes, data structures with invariants are easier to reason about. The authoritative server can apply the change locally to detect if invariants are violated. If they are, instead of broadcasting the change, it can notify the sender that there is a conflict.
Overthinking things
Developers may find it tempting to treat collaborative applications as any other distributed systems, and in many ways that’s a useful way to look at them. But they differ in an important way, which is that they always have humans-in-the-loop. As a result, many edge cases can simply be deferred to the user.
For example, every multiplayer application has to decide how to handle two users modifying the same object concurrently. In practice, this tends to be rare, because of something I call social locking: the tendency of reasonable people not to clobber each other’s work-in-progress, even in the absence of software-based locking features. This is especially the case when applications have presence features that provide hints to other users about where their attention is (cursor position, selection, etc.) In the rare times it does occur, the users can sort it out among themselves.
A general theme of successful multiplayer approaches we’ve seen is not overcomplicating things. We’ve heard a number of companies confess that their multiplayer approach feels naive — especially compared to the academic literature on the topic — and yet it works just fine in practice.
When CRDTs make sense
Although CRDTs aren’t always the best solution for always-online collaborative apps, it’s still fascinating tech that has real use cases.
Ink & Switch, the exceedingly capable team behind the popular CRDT library Automerge, have a compelling vision for Local-first software, which makes heavy use of CRDTs. Apps that need to run offline in general are good candidates for CRDTs.
I’ve also read some posts lately extolling the virtues of CRDTs for text, especially plain text. I’m not up on text synchronization except to know that it presents its own challenges, so the fact that the people who have given it a lot of thought are landing on CRDTs is a strong signal in their favor.
For more like this, subscribe to our Browsertech Digest or follow @JamsocketHQ on Twitter.